Breaking health care data silos with federated learning models
Learn how federated learning models can impact health care.
"Data is a precious thing and will last longer than the systems themselves.” This quote by Tim Berners-Lee, inventor of the World Wide Web, depicts the reality of our world in today’s day and age.
Technological advances are transforming the way we look at care delivery. With the advent of artificial intelligence (AI), machine learning (ML), deep learning, and advanced analytics, caregivers can deliver faster and more accurate diagnosis and treatment.
However, there are still many roadblocks to our aim of providing easy access to quality care at lower cost and the most fundamental of them is access to accurate and reliable health data.
Training an algorithm to aid, diagnose and treat complicated illnesses requires a large database encompassing the full spectrum of possible anatomies, pathologies, and health information of the member.
But it is difficult to gather such vast and accurate health information about large population groups. A lot of valuable information that exists is not accessible due to due to privacy, regulatory, legal, and ethical challenges associated with data sharing. This is where federated learning models can be a game changer.
Challenges with traditional ML models
IDC research reflects that health care data will grow at 36% CAGR by 2025. Further, in health care, the global big data market is expected to reach $34.27 billion by 2022 at a CAGR of 22.07%. Handling this literal deluge of data will be a challenge, not to mention mining it for relevant and actionable insights.
Some of the typical hindrances that the health care organizations could face include different standards being adopted for collating and analyzing data by different organizations. Also, organizations that have invested in data research are likely to explore the competitive advantage of data and may not be open to data sharing.
Data privacy and security regulations also have a key role to play in providing access to data, driven by the fact that patients may feel apprehension in sharing their personal medical history with researchers/health care professionals worldwide.
Such situations make a traditional machine learning model less viable as it can introduce complexities around fairness and bias associated with the model unviable. In such a setup, an organization would collect data from various sources into a central lake, analyze it, to draw insights relevant to the population.
This kind of approach has its own set of challenges in terms of discovering emerging patterns quickly. Also, since the data exists in silos and is protected by regulatory laws, it is likely to provide less accurate actionable clinical outcomes owing to the fragmented nature of data.
What is a federated learning model?
Under federated learning, an algorithm is trained across multiple decentralized data sources like edge devices or servers holding local data samples, without having to exchange the data sets. Since the model goes to the data residing across multiple locations and owners, and only draws certain metadata for analysis, the privacy and security of data remain intact.
The model works on an iterative method wherein the most recent combined model is distributed across local nodes and the insights from each node is then aggregated back to the combined model. This process is repeated again and again thereby training the algorithm to build a consensus model.
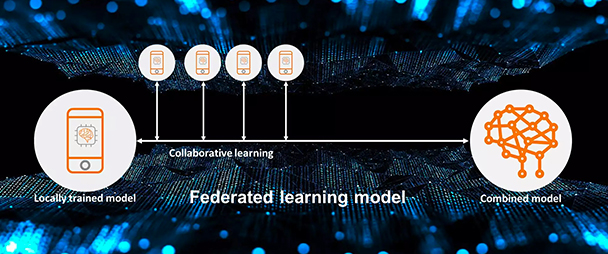
-
OR
What this means for health care organizations is that they can get actionable insights from the data, without having to source or own it, taking away the concerns of cost of procurement and storage, in addition to doing away with many regulatory and privacy concerns.
The trained model can be shared across different health care providers who can add their own data on top of the shared model and the final model can be reconciled into a consensus model that has gained knowledge from each provider and is therefore clinically more timely and relevant.
Such a model where we augment a provider with timely machine intelligence is likely to find acceptance in cases such as:
- Using predictive data analytics for determining hospital readmission risks based on patients’ electronic health records (EHRs)
- Early detection of diseases or propensity to suffer from diseases such as tuberculosis or kidney disease
- Ascertaining the effectiveness of the drug across different sections of the population-gender, age, genetic profile, etc.
Pros and cons of federated learning models
Federated learning models provide numerous benefits:
- They allow for collaborative learning from edge devices, which provides a vast data set for training models, without the need for uploading or storing data on a centralized server, which saves hardware infrastructure costs.
- Since personal data of the edge device users remain at their end, there are limited concerns of data security.
- They can also enable local real-time predictions as there is no lag due to data transmission.
However, the model does come with its own set of challenges:
- Primarily there is the issue of data quality. Since the data resides on large number of edge devices, it is imperative to standardize the inputs to model from various different sources."
- Federated learning models are more prone to be affected by malicious/fake data flowing in from the edge devices, also termed as “data poisoning.”
Future of federated learning in health care
Federated learning is a promising approach to instill a wide range of innovations in the field of digital health. By enabling collaborative training of AI-based models without the need for a centralized data set, the technique is already making an impact across the entire care delivery cycle ranging from improved medical image analysis to collaborative drug discovery.
Overall, the field is still evolving, and will be an active area of research. Though it does have the potential to help people live healthier lives and help make the health system work better for everyone.